
减少储存 KV Cache 的内存浪费
让 KV Cache 在请求中和请求间弹性共享以减少内存使用
现状:分配连续内存以储存张量(浪费大量空间)
核心方法:PagedAttention 和 KVBlock 管理
PagedAttention
将 KV Cache 分块成 KV Block,允许将连续的 key 和 value 向量存储到不连续的内存中。
每个 KV Block 包含固定数量 token 的 key、value 向量。
内存管理机制
内存被分割为固定大小的 Physical Page。
用户程序的 Logical Page 映射到 Physical Page,因此连续的 Logical Page 可以映射到不连续的 Physical Page 上。
物理内存空间无需提前预留。
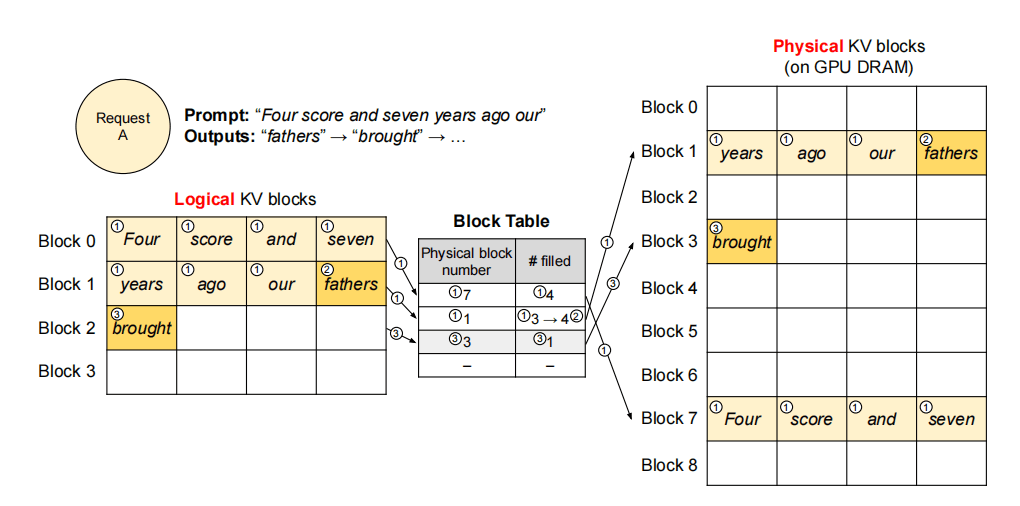
vLLM 将一个请求的 KV Cache 表示为一串 Logical Block,在生成过程中从左往右依次填充。
Block Engine
在 GPU Worker 上,Block Engine 申请一块连续的 GPU RAM,并分割为 Physical Block。
CPU 端也进行相同操作,用于换入换出。
K-V Block Manager 维护 Block Table,其中每个 Entry 记录了 Logical Block 对应的 Physical Block 以及已填充的数量。
解码迭代流程
vLLM 在每轮 decoding 时选择一组候选序列做 batching。
为新的 Logical Block 分配对应的 Physical Block。
本轮所有输入 token 拼接为一个序列,送入 LLM。
在计算时,PagedAttention 从 Logical Block 中读取已有 KV Cache,并写入新的 KV Cache。
优化效果
vLLM 将单个请求的内存浪费限制到 1 个 Block 内。
提升内存利用率,可将更多请求 batch 在一起,提升吞吐。
当请求生成结束后,KV Block 会被释放,用于新的请求。
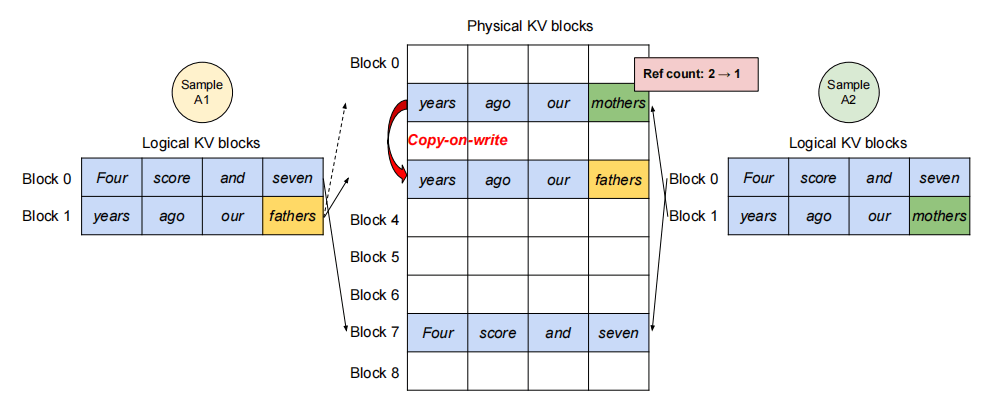
用于同一个 prompt 生成多个候选输出,供用户选择最佳响应。
进入生成阶段后,不同采样分支需要独立的 KV Cache。
vLLM 在 块粒度 实现了 写时复制:仅在块需要被修改时才复制。
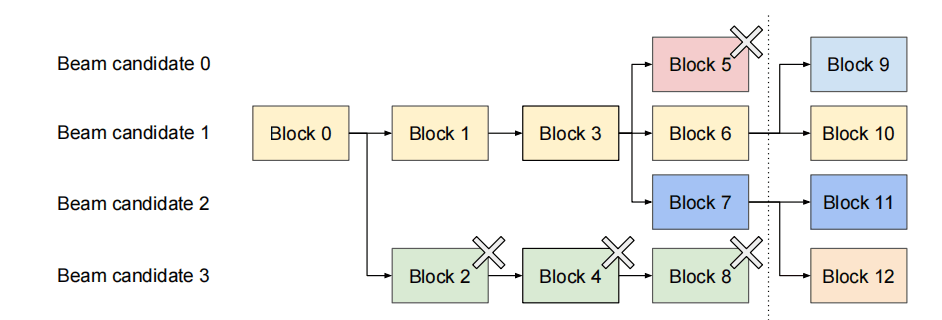
序列生成常用的启发式搜索算法,每步保留 Top-K 候选。
vLLM 通过物理块共享减少频繁拷贝:
大部分块可在不同 beam 之间共享。
仅当新 token 落在共享块内时才触发复制。
许多请求包含相同的 system prompt(任务描述 + few-shot 示例)。
LLM 服务方可提前缓存前缀部分的 KV Cache,避免重复计算。
类似操作系统共享库:用户请求只需映射到共享的物理块,计算仅针对用户输入部分执行。
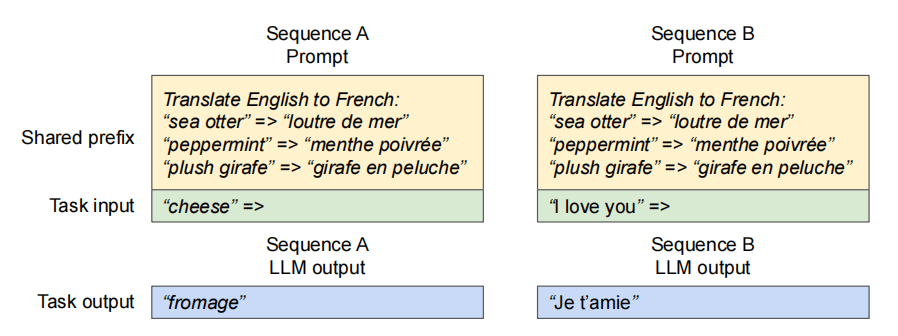
vLLM 通过 统一的映射层 屏蔽复杂的共享细节。
LLM 内核只需看到每条序列的物理块 ID 列表,而不关心共享模式。
不同采样需求的请求也能批处理,提高吞吐量。
当物理内存用尽时,需要驱逐部分块。主要问题:
驱逐哪些块?
如何恢复被驱逐的块?
驱逐策略
基于启发式预测“最远未来访问”的块。
要么驱逐整个序列的全部块,要么一个也不驱逐。
恢复机制
交换:将被驱逐的块转移到 CPU 内存。
重算:直接重新计算对应的 KV Cache。
Comments (0)