
SGLang 的设计目标有两个:
- 简化 LLM 程序编写过程
- 提高 LLM 程序执行效率
在传统 LLM 应用开发中,存在一些痛点:
- 需要大量字符串操作(prompt 拼接、解析输出)
- prompt 调优依赖试错,过程不可预测
- 输出解析脆弱,LLM 格式变化就可能失败
- 并行调用多个实例需要手动实现
SGLang 的核心思路是:
把 prompt 当作状态流 —— 可追加、可分支、可合并。
- += 表示追加
- fork/join 表示分支和合并
- gen/select 表示生成或选择
- 其余逻辑直接用 Python
执行模式上,SGLang 提供两种方式:
1. 解释器模式:边运行边调度
2. 图编译模式:先编译为静态图,再批量并行执行
现有系统中,多个调用常常共享相同前缀,但无法有效重用 KV Cache,造成重复计算和显存浪费。
在 JSON 等约束解码场景下,LLM 输出必须符合语法规则。现有系统用 FSM 逐 token 检查,解码过程冗余。
RadixAttention 用 基数树 (Radix Tree) 来管理 KV 缓存:
- 将 token 序列映射到 KV 张量
- 支持高效前缀搜索、插入和逐出
- 节点以分页方式存放显存,并有引用计数
- 驱逐策略:LRU 叶子优先
- 完全兼容连续批处理、PagedAttention、张量并行
- 批处理请求时,按最长公共前缀优先排序(近似 DFS)
运行时流程:
1. 前端发送完整提示
- 后端前缀匹配 → 命中则直接复用 KV
- 未命中 → 插入新节点
2. fork 时
- 前端先发“前缀 hint”,复制出多个分支
- 后端保证它们共享同一 radix 节点,并锁定计数
- 前端再发剩余 token
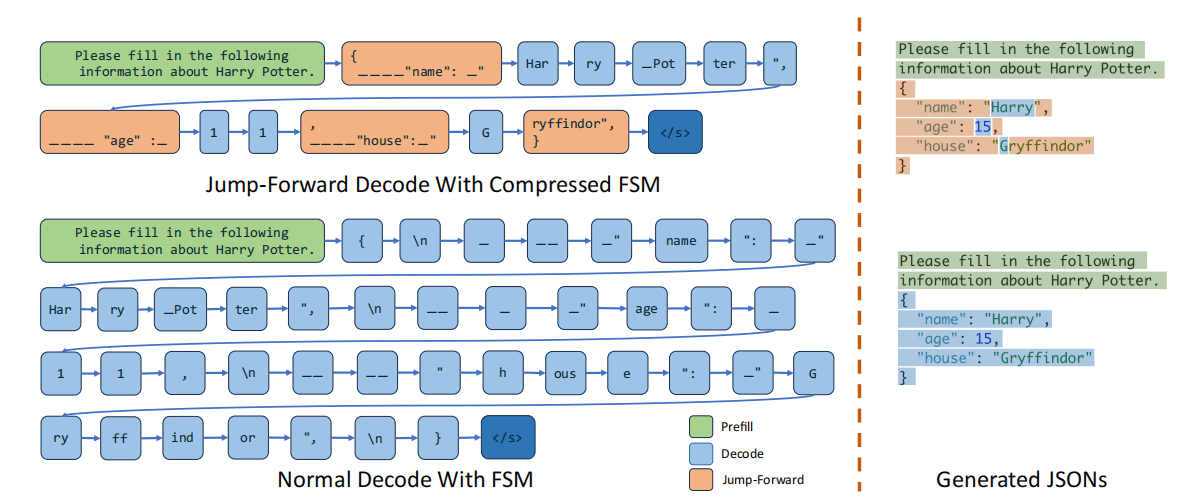
现有 FSM:逐 token 检查非法词,无法一次解码连续片段。
SGLang 的改进:
- 将相邻的单一转移合并为“压缩边”
- 识别出可一次解码的 token 序列
- 一次前向推理即可输出整段固定内容
- 通用于所有正则表达式,无需修改模型
SGLang 对黑盒 API 模型也有优化:
- 首次调用
- 临时关闭 stop 条件,多生成 k 个 token
- 增量文本被缓存
- 后续调用
- 本地前缀匹配,命中则直接复用
- 匹配失败时回退到正常调用
核心思路:推测执行
-让模型在首次调用时预生成更多 token,把可能的后续结果缓存下来。
-命中即可减少一次 API 调用,降低延迟和 token 成本。
Comments (0)